
Программа
TextPipe Pro предоставляет огромные возможности по обработке текстовых файлов.
Но не смотря на довольно большое количество учебных и демонстрационны материалов, освоить эту программу не всегда легко удаётся.
Для того, чтобы продемонстрировать на конкретном примере возможноси программы
TextPipe Pro, я подготовил этот небольшой мануал.
Он не даёт ответов на все вопросы, но он поможет тем, кто начинает осваивать эту программу, сделать в ней первые шаги. А дальше, поверьте, освоение пойдёт гораздо проще.
Все рабочие материалы к этому мануалы я залил одним файлом на рапиду. Можете скачать отсюда.
Я буду ссылаться в тексте на некоторые файлы из этого комплекта. Но на самом деле качать его не обязательно - если повторять по шагам все описанные операции, всё будет и так понятно.
Итак, возьмём вот такую распространённую задачу: нужно из HTML-кода страницы с интересующей нас статьёй выделить только текст статьи и заголовок, удалив всё лишнее.
Для чего это может быть нужно?
Например для сбора текстов, их дальнейшей обработки (синонимайзинг, рерайт, перевод) и наполнения своих сайтов.
Возьмём случайную статью. Например эту: http://stroybm.ru/articles/kadry/20090624134642/index.html
Исходный код в приложенном файле "
html_code_text.txt"
Для начала нужно выделить код только статьи из кода всей страницы. Это решается заменой. И я с этим сам всегда мучаюсь.
Суть простая. Найти какой-то неповторимый элемент страницы ДО основной статьи и сразу ПОСЛЕ неё.
И потом заменить по типу "Всё до, включая..." и потом "Всё после начиная с..."
В нашем случае уникальный элемент "ДО", это

Чтобы TextPipe заменил всё от начала страницы до этого элемента (включая его), нужно задать ему команду:
Поиск и замена -> Найти схему (стиль old egrep)Указать в поле для данных:
 Выбрать Action -> Remove
Выбрать Action -> RemoveИ всё. Он удалит нам всё до этой строки.
Скрин (
все картинки кликабельны):

Теперь пройдём по поряду по коду этой строки, чтобы было понятно для чего тут что.
Итак. Ещё раз. Оригинал уникальной строки:
а изменённая строка:
. - это любой знак, т.е. мы говорим программе: "Ищи любой знак"
* - это любое количество, т.е. мы добавляем программе "Ищи любое количество любых знаков"

- это наш уникальный код, в который вставлен экранирующий символ "\"
этот знак говорит программе - то что стоит за этим знаком, это не программный код (не спецсимвол для макроса), а обычный текст.
Т.е. программа при обработке такой строки знаки "\" просто выкидываются.
Я экранирую всё что может быть расталковано как спецсимволы. Фактически, список этих символов определён, его можно изучить по help`у.
Но если есть сомнение, спецсимвол в коде или нет - его лучше заэкранировать. Это позволит измежать массы возможных проблем с отладкой макроса.
Проверить что получилось на промежуточном этапе можно запустив учебный прогон:

Теперь нужно удалить всё лишнее после текста.
В этом случае уникальный элемент текста:

Можно заметить, что такой элемент встречается несколько раз, но для нас это не критично, т.к. он встречается сразу после текста, а не внутри него,
так что мы дадим программе задачу найти первый попавшийся элемент
и удалить всё, что идёт за ним.
Это также делается при помощи команды:
Поиск и замена -> Найти схему (стиль old egrep)Вот так будет выглядеть команда:


В итоге при учебном прогоне получаем текст самой статьи, обрезанный спереди и сзади (файл
text_article_cutted_front_end.txt).
Но в нём остаётся много мусора.
Ссылки, пустые строки.
Это мы сейчас оперативно и просто почистим.
Для того, чтобы убрать вообще все тэги в статье (к сожалению, это "убьёт" и все картинки и оформление, которое возможно, хотелось сохранить).
Это самый простой способ. Универсальный. Для каких-то конкретных случаев можно придумать более сложный вариант очистки кода, но пока не будем углубляться.
Удалить -> HTML and XML -> Remove all tags
Ну и сразу удалим пустые строки из статьи, если они нам не нужны.
Удалить -> Пустые строки
В итоге получаем вот такой вот обработанный текст (файл
text_article_cutted_2.txt)
В этом файле всё ещё остаётся очень много мусора.
Например:

Также есть табуляции, и прочие мешающие нам элементы.
Добавим ещё пару команд:
Поиск и замена -> Найти точноВводим то, что нужно заменить. Конкретно:
В
Action выбираем
RemoveЛибо можем выбрать
Replace и заменить на пробел. Но в нашем случае
Remove будет корректнее.
Обязательно проверяем, чтобы не была поставлена галочка
"Замена только первого". Иначе не весь текст будет очищен от этого символа.
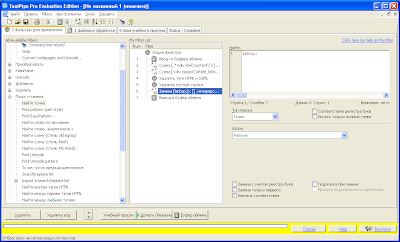
А также добавляем команду удаления многих пробелов идущих подряд:
Удалить -> Многие пробелы
То что получилось, уже гораздо лучше, но всё ещё содержит не нужные нам строки, такие как:

А также есть поробелы в начале строки, и пустые строки в конце статьи. Ну и автор. Нужен он нам или нет? Покажу пример, когда не нужен.
То что осталось проще всего обработать удалением строк по номерам.
Лично я так и делаю. Наверняка есть более элегантные и универсальные способы. Но у меня получается этот. Его и продемонстрирую.
Удалить -> Удалить строки -> Удалить диапазон строкУказывае нужные диапазоны. Чтобы удалить первую пустую строку это будет 1 и 1:

Для блока, идущего после названия статьи (имеем ввиду, первая строка уже удалена, строки сместились и отсчитывать теперь нужно от новой первой строки - названия, т.е. со 2-й по 7-ю строки):

Теперь удаляем строки с конца файла. Если хотим убрать и данные об авторе, убираем последние 6 строк. Если хотим оставить информацию об авторе, тогда нам надо удалить 4 строки с конца файла.

Как финальный штрих - убираем пробелы в начале строк:
Удалить -> Пустоты в начале строки
Всё, вот такой вот итоговый текст мы получили: (файл
text_article_final.txt)
Если его закидывать в Wordpress в виде HTML, то больше чистить его не нужно.
Если будем использовать его как текст, то нужно вычистить также такие символы:

ну и другие, которые остались в тексте после всех наших манипуляций.
Делается это также:
Поиск и замена -> Найти точноВводим то, что нужно заменить.
В Action выбираем Remove
Я это делаю не всегда.
Т.к. в большинстве сучаев такие элементы мне уже не мешают.
Вот, собственно, и всё. Можно в синонимазер статью закидывать, можно сразу публиковать.
Для того, чтобы статья сохранилась в текстовый файл, нужно будет настроить вывод.
Вместо "
Выводить в буфер обмена" (последняя строка макроса), заменяем настройки как показано на рисунке:
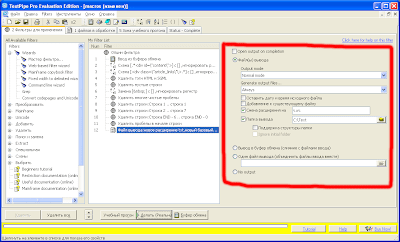
Все настройки, по моему, вполне понятны. Варьировать можно под свои нужды.
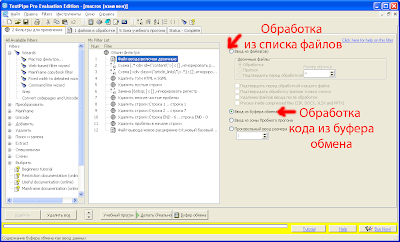
А для того, чтобы TextPipe знал что ему, собственно, обрабатывать, все исходные файлы со статьями (в нашем случае это 1 файл) нужно добавить в список файлов в обработке:

Для этого нужно просто перетащить нужный файл из проводника в окошко TextPipe Pro.
Кроме того, как в моём примере, можно скопировать содержимое обрабатываемой страницы в буфер обмена Windows и запустить обработку.
Настраивается источник для обработки в самой первой строке фильтра:
Проверяем как всё работает - запускаем реальный прогон.

В сервисном окошке нам покажут все проводимые операции:

Если при обработке возникнут ошибки - они будут показаны красным.
Обработанный материал сохраняется в текстовом файле в папке, которую мы указали.
Если мы обрабатывали данные из буфера - это будет 1 файл. Если брали список файлов - то несколько.
Можно также все файлы сохранять в 1 итоговый текстовый файл. Это настраивается в последнем шаге макроса:
Один файл вывода (объединить файлы вывода вместе).
Кстати, есть ещё два момента.
Если сначала сделать удалить все пробелы в начале строк, а потом убрать пустые строки, то весь текст получится одним большим куском, без пустых строк между абзацами.
Для восприятия человеком это не так удобно. Но для говноблогов, доров и т.п. - вполне подойдёт.
Тогда немного меняется удаление лишних строк. Но тут, как говорится, кому как удобнее.
И второе - наш макрос мы составили для обработки конкретного кода, конкретной страницы.
Проделывать такую работу ради создания макроса для обработки одной единственной страницы - безсмысленно.
Но в большинстве случаев, статьи на сайте имеют типовой формат. Это относится к блогам, каталогам статей и т.п.
Там, где используется какая-то CMS, почти всегда все статьи имеют одинаковый формат (или очень близкий), поэтому написав макров для обработки одной статьи, мы автоматически имеем возможность обработать все статье и с этого сайта.
Но только с этого сайта. Для других нам придётся немного (а иногда полностью) менять код макроса, создавая его по тому-же принципу, как я расписал выше.
Давайте проверим.
Берём ещё какую-нибудь статью с того-же сайта. Например:
http://stroybm.ru/articles/nedvijimost/20090610092658/index.html
Статья, как и в первом случае, выбрана совершенно случайно.
Берём её код (файл
html_code_text_2.txt) и помещаем в зону учебного прогона.
Делаем учебный прогон ничего не меняя в настройках макроса.
Сделали и получили отлично обработанный текст (файл
text_article_final_2.txt).
Вуаля! У нас готов макрос для обработки всех статей с сайта http://stroybm.ru/.
Не плохо.
Готовый макрос я также залил (файл
macros.fll).
Вот, собственно, таким образом можно обрабатывать тексты для наполнения своих сплогов.


































